DreamHackの監視 - 世界最大のデジタルフェスティバル
2015年6月24日筆者: Christian Svensson (DreamHack Network Team)
編集者注: この記事はPrometheusユーザーによるゲスト投稿です。
1万人以上の要求の厳しいゲーマーのネットワークを運用しているなら、ネットワーク内で何が起こっているのかを本当に知る必要があります。ああ、そしてすべてを5日間でゼロから構築しなければなりません。
もしDreamHackという名前を初めて聞いたのであれば、このイベントはこうです:2万人の人々を集め、その大多数に自分のコンピュータを持ってきてもらうのです。プロフェッショナルゲーミング(eSports)、プログラミングコンテスト、ライブ音楽コンサートを混ぜ合わせます。その結果、デジタルなあらゆるものに特化した世界最大のフェスティバルが誕生します。
このようなイベントを実現するためには、多くのインフラストラクチャが必要です。この規模の通常のインフラストラクチャの構築には数ヶ月かかりますが、DreamHackのクルーはわずか5日間でゼロからすべてを構築します。これには、ネットワークスイッチの設定はもちろん、電力配分の構築、飲食物の店舗の設置、さらには実際のテーブルの建設なども含まれます。
ネットワークに関連するすべてを構築・運用するチームは、正式にはネットワークチームと呼ばれますが、通常は自分たちをtechまたはdhtechと呼んでいます。この記事では、dhtechの仕事と、2015年夏のDreamHackでPrometheusを使用して監視をさらにレベルアップさせようとした方法に焦点を当てます。
機器
1万台以上のコンピュータに対応する高性能ネットワークを構築するには、少なくとも同数のネットワークポートが必要です。私たちの場合は、約400台のCisco 2950スイッチがこれにあたります。これらをアクセススイッチと呼んでいます。これらは、参加者がコンピュータを持ち込む会場のいたるところに配置されます。

当然、これらのコンピュータをスイッチに接続するだけでは十分ではありません。そのスイッチは他のスイッチにも接続される必要があります。ここで、ディストリビューションスイッチ(またはディストスイッチ)が登場します。これらは、すべてのアクセススイッチからの数百のリンクを集約し、より管理しやすい10 Gbit/sの高容量ファイバーに集約するスイッチです。ディストスイッチはさらにコアに集約され、トラフィックは宛先にルーティングされます。
これらすべてに加えて、独自のWiFiネットワーク、DNS/DHCPサーバー、その他のインフラストラクチャを運用しています。完成すると、私たちのコアは下の画像のようなものになります。
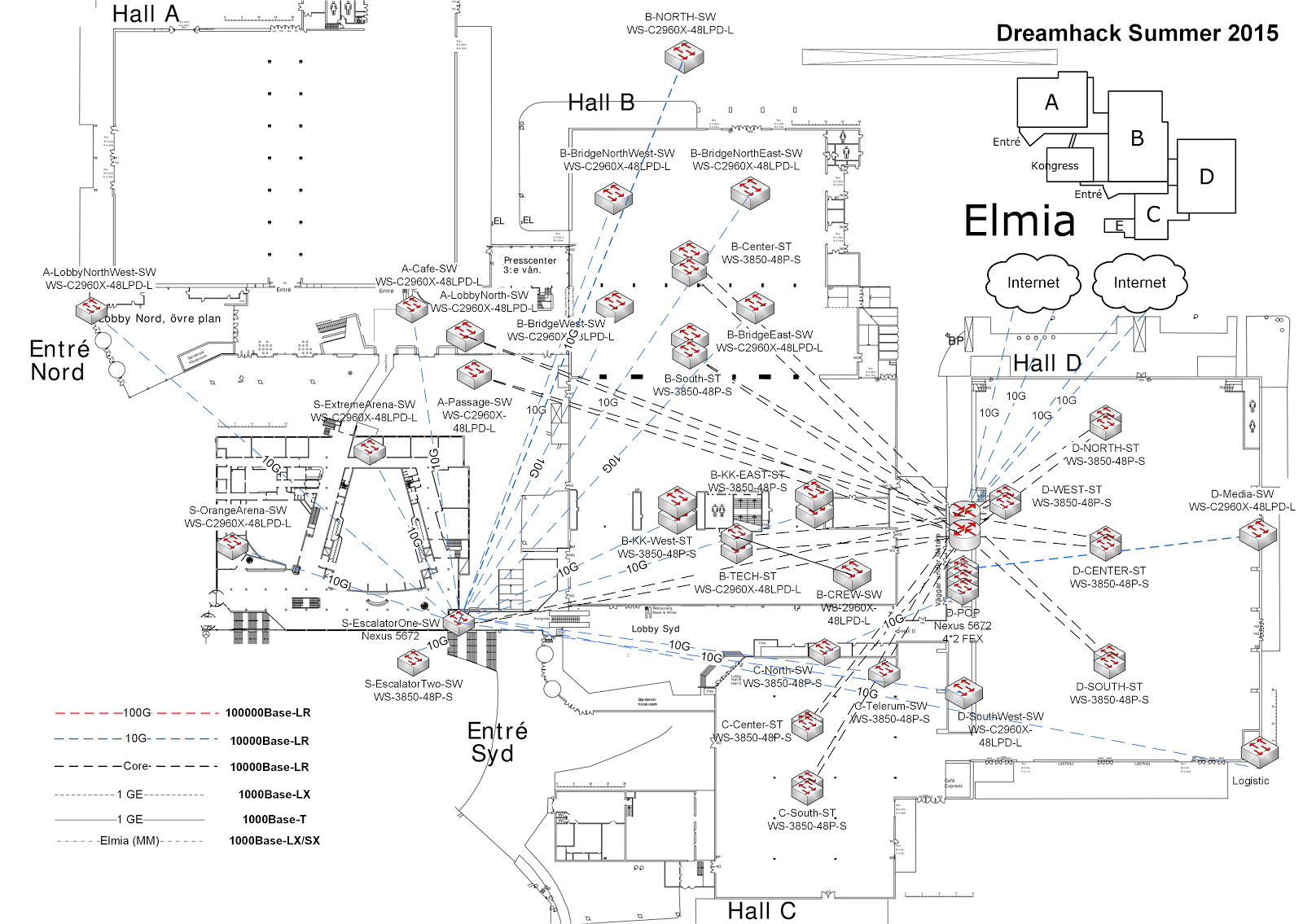
すべてを合わせると、監視すべきものが長くなっていきますので、本題に入りましょう:どうすれば何が起こっているかを知ることができるのでしょうか?
紹介:dhmon
dhmonは、ネットワークを監視するだけでなく、他のチームが好きなメトリクスを収集できるシステム群の総称です。
ネットワークは5日間で構築する必要があるため、監視システムが簡単にセットアップでき、最後のインフラストラクチャ変更(デバイスの追加または削除など)が必要な場合に同期を維持できることが不可欠です。ネットワークの構築を開始すると、機器の不具合や予期せぬ問題を発見するために、できるだけ早く監視が必要になります。
過去には、Cacti、SNMPc、Opsviewなど、一般的に利用可能なソフトウェアを組み合わせて使用しようとしました。これらは機能しましたが、クローズドシステムとしての性格が強く、最小限の機能しか提供しませんでした。数年前、チームの数人が「もう十分だ、自分たちでより良くできる!」と言い、カスタム監視ソリューションを書き始めました。
当時、選択肢は限られていました。長年にわたり、システムはGraphite(スケーラビリティの問題)、カスタムCassandraストア(高い複雑性)、InfluxDB(未熟なソフトウェア)を使用し、最終的にPrometheusの使用に落ち着きました。私は2014年にJulius Volzに会ったときにPrometheusのことを初めて知り、以来ずっと試してみたいと思っていました。この夏、ついに私たちが書いたカスタムInfluxDBベースのメトリクスストアをPrometheusに置き換えました。ネタバレ:もう元には戻りません。
アーキテクチャ
監視ソリューションは、コレクション、ストレージ、プレゼンテーションの3つのレイヤーで構成されています。最も重要なコレクターはsnmpcollector(SNMP)とipplan-pinger(ICMP)で、それにdhcpinfo(DHCPリース統計)が続きます。また、他のシステムの統計情報をnode_exporterのtextfileコレクターにダンプするスクリプトもいくつかあります。
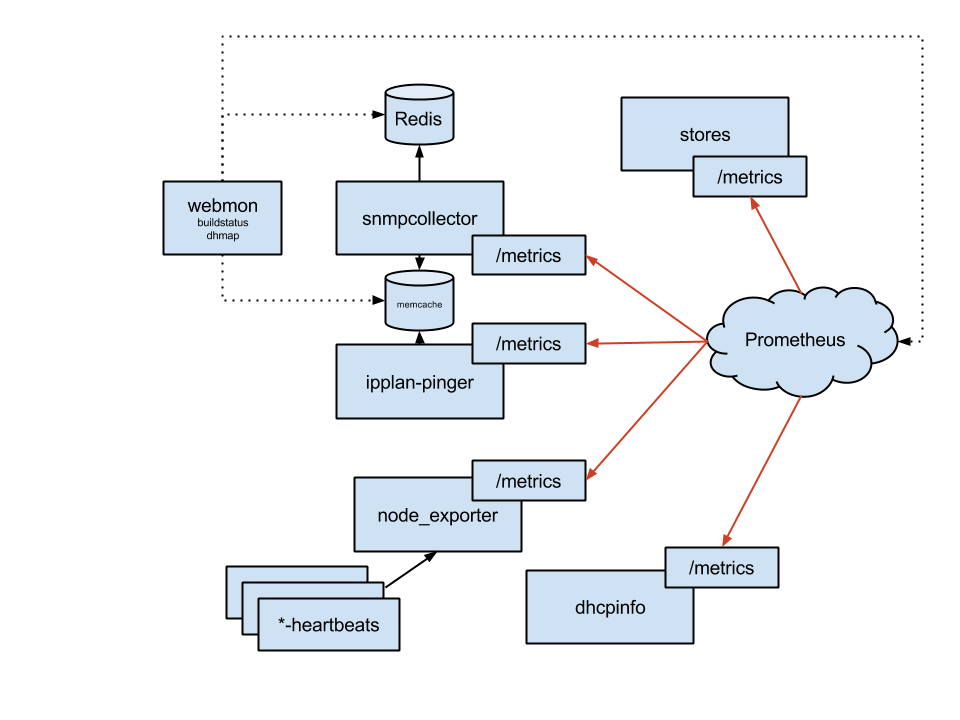
Prometheusを中央の時系列ストレージおよびクエリエンジンとして使用しますが、Redisとmemcachedも使用して、Prometheusに意味のある方法で保存できないバイナリ情報を収集したスナップショットビューをエクスポートしたり、非常に新しいデータにアクセスする必要がある場合に使用したりします。
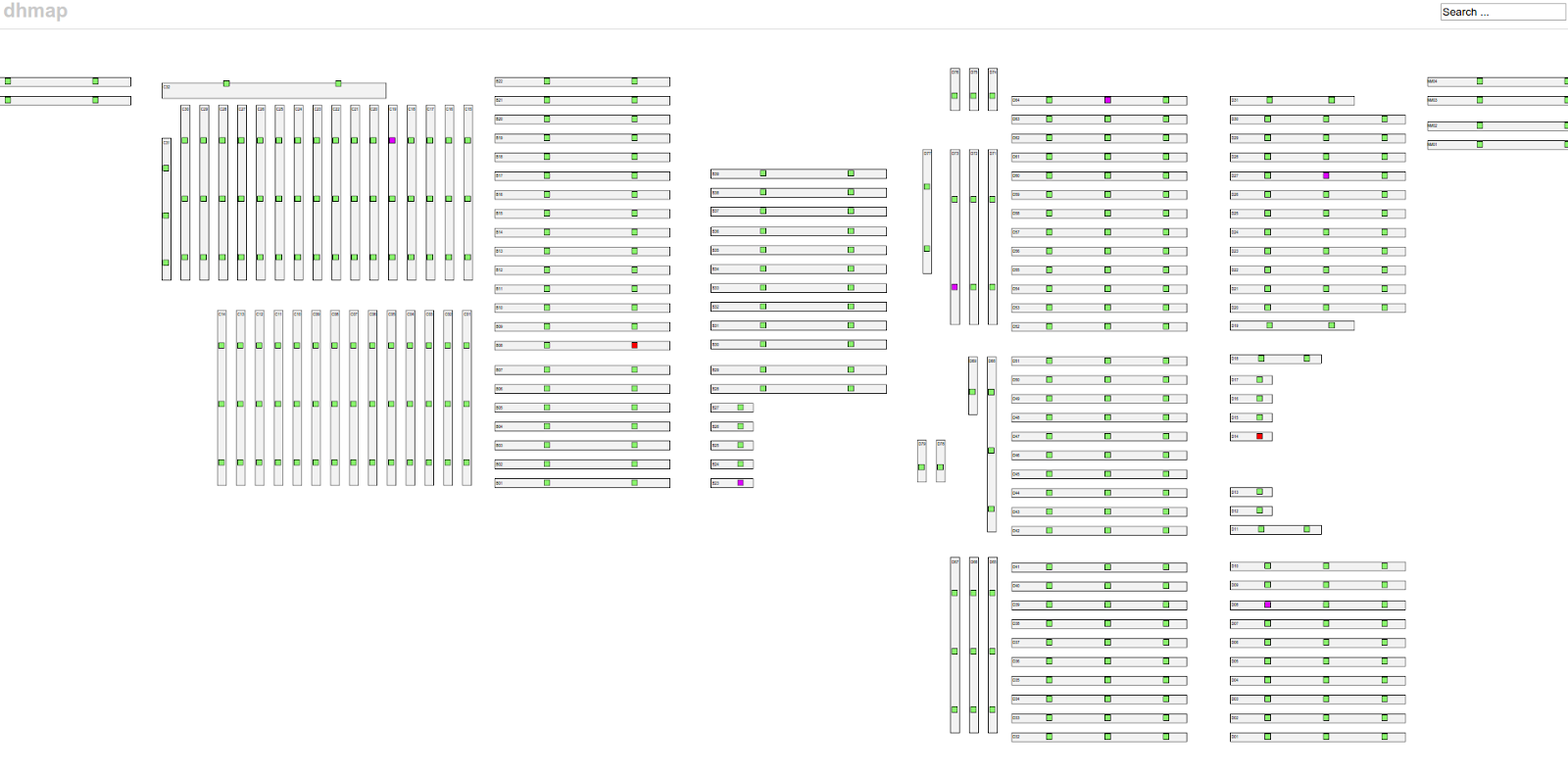
その一例がプレゼンテーションレイヤーです。dhmap Webアプリケーションを使用して、アクセススイッチの全体的な健全性の概要を把握しています。エラーを効果的に解決するためには、データ収集からプレゼンテーションまでのレイテンシが約10秒である必要があります。目標は、顧客が気づく前、または少なくともサポート担当者に問題を報告するために歩いていく前に問題を解決することです。このため、最新のスナップショットネットワークにアクセスするために、当初からmemcachedを使用しています。
今年は低レイテンシデータにmemcachedを引き続き使用し、履歴データやレイテンシにそれほど敏感ではないすべてのデータにPrometheusを使用しました。この決定は、Prometheusが非常に短いサンプリング間隔でどの程度パフォーマンスを発揮するか確信が持てなかったためです。結局、このデータにもPrometheusを使用できる理由はないと判断しました。次のDreamHackでは、memcachedをPrometheusに置き換えることを間違いなく試します。
Prometheusセットアップ
これまでPrometheusとして参照されてきたブロックは、実際には3つの製品で構成されています:Prometheus、PromDash、そしてAlertmanagerです。セットアップは非常に基本的で、3つのコンポーネントすべてが同じホストで実行されています。すべては、リバースプロキシとして機能するApache Webサーバーによって提供されています。
ProxyPass /prometheus https://:9090/prometheus
ProxyPass /alertmanager https://:9093/alertmanager
ProxyPass /dash https://:3000/dash
ネットワークの探索
Prometheusは、ネットワーク全体から収集されたストリーミング情報で非常にクールなことを実行できる強力なクエリエンジンを持っています。しかし、クエリが処理すべきデータ量が多すぎて、合理的な時間内に完了しない場合があります。これは、約18,000のリンクのうち、上位5つの使用率の高いリンクをグラフ化しようとしたときに発生しました。クエリは機能しましたが、タイムアウト設定時間とほぼ同じ時間がかかり、遅くて不安定でした。このため、重いクエリを事前に計算するPrometheusのレコーディングルールを使用することにしました。
precomputed_link_utilization_percent = rate(ifHCOutOctets{layer!='access'}[10m])*8/1000/1000
/ on (device,interface,alias)
ifHighSpeed{layer!='access'}
これにより、topk(5, precomputed_link_utilization_percent)の実行は非常に高速になりました。
受動的になる:アラート
この段階で、ネットワークの状態をクエリできるものができました。人間である私たちは、物事が正常に動作しているかを確認するために常にクエリを実行する時間を費やしたくないので、当然アラートが必要になります。
例えば:すべてのアクティブスイッチがGigabitEthernet0/2をアップリンクとして使用していることはわかっています。ネットワークケーブルが長期間保管されて酸化し、望ましい1000 Mbpsをネゴシエートできなくなることがあります。
ネットワークポートのネゴシエートされた速度は、SNMP OID IF-MIB::ifHighSpeedで見つけることができます。しかし、SNMPに詳しい人なら、このOIDが任意のインターフェイスインデックスによってインデックス化されていることに気づくでしょう。このインデックスに意味を持たせるためには、SNMP OID IF-MIB::ifDescrからのデータとクロスリファレンスして、実際のインターフェイス名を取得する必要があります。
幸いなことに、snmpcollectorは、Prometheusメトリクスを生成する際に、このようなクロスリファレンスをサポートしています。これにより、データをクエリできるだけでなく、有用なアラートを定義することもできます。私たちのセットアップでは、SNMPコレクションを設定して、IF-MIB::ifTableおよびIF-MIB::ifXTable OIDの下のすべてのメトリクスにifDescrをアノテートしました。これは、GigabitEthernet0/2ポートのみに関心があり、他のインターフェイスは対象外であることを指定する必要がある場合に役立ちます。
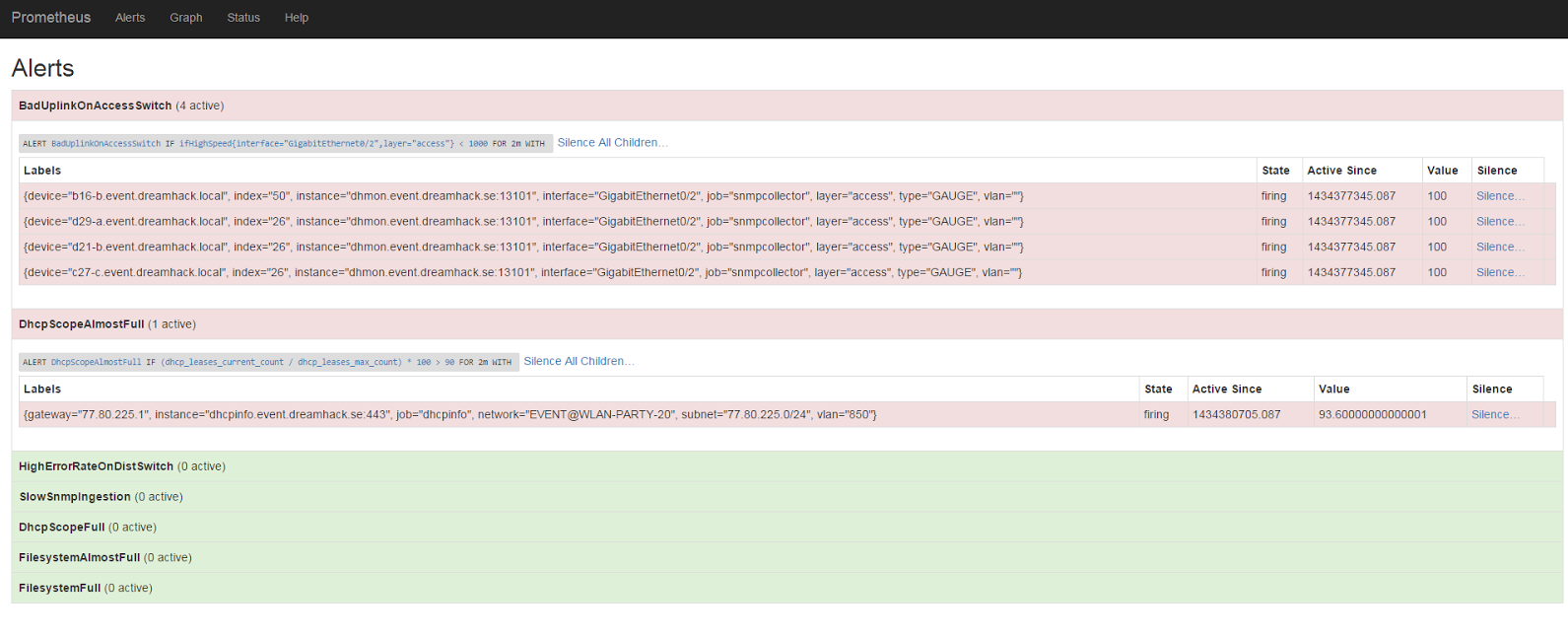
このようなアラート定義がどのように見えるか見てみましょう。
ALERT BadUplinkOnAccessSwitch
IF ifHighSpeed{layer='access', interface='GigabitEthernet0/2'} < 1000 FOR 2m
SUMMARY "Interface linking at {{$value}} Mbps"
DESCRIPTION "Interface {{$labels.interface}} on {{$labels.device}} linking at {{$value}} Mbps"
完了!これで、スイッチのアップリンクが最適でない速度でリンクした場合にアラートを受け取ることができます。
ほぼ満杯のDHCPスコープのアラート定義がどのように見えるかについても見てみましょう。
ALERT DhcpScopeAlmostFull
IF ceil((dhcp_leases_current_count / dhcp_leases_max_count)*100) > 90 FOR 2m
SUMMARY "DHCP scope {{$labels.network}} is almost full"
DESCRIPTION "DHCP scope {{$labels.network}} is {{$value}}% full"
アラートを定義する構文は、Prometheusや時系列データベースの経験がない人でも、読みやすく理解しやすいと感じました。
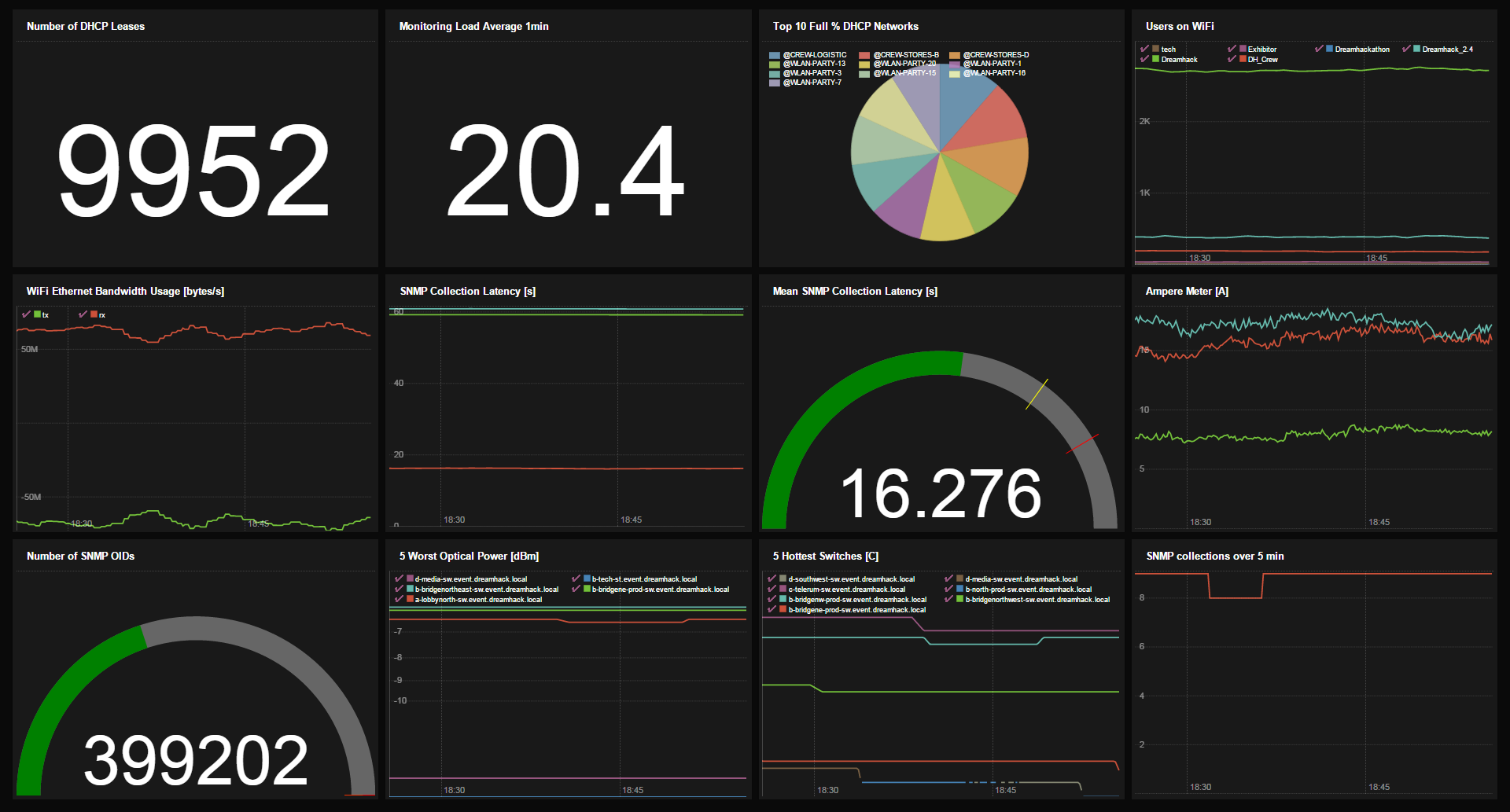
能動的になる:ダッシュボード
アラートは監視の不可欠な部分ですが、時にはネットワークの健全性の概要を把握したいだけの場合もあります。これを実現するために、PromDashを使用しました。ネットワークについて尋ねられるたびに、回答を得るためのクエリを作成し、ダッシュボードウィジェットとして保存しました。最も興味深いものは、誇らしげに表示した概要ダッシュボードに追加されました。
未来
システムの不可欠な部分を変更するのは複雑な作業であり、1つのイベントでPrometheusを統合できたことを嬉しく思いますが、改善の余地は間違いなくたくさんあります。基本的なものとしては、パフォーマンスを向上させるために事前計算されたメトリクスをさらに使用する、アラートを増やす、既存のアラートを調整するなどがあります。もう1つの領域は、オペレーターにとってより簡単にすることです。ネットワークオペレーションセンター(NOC)に適したアラートダッシュボードを作成する、オンコール担当者をページングするか、NOCにアラートをエスカレーションさせるかなどを決定することです。
計画しているより大きな機能としては、syslog分析(syslogがたくさんあります!)、侵入検知システムからのアラート、Puppetセットアップとの統合、およびDreamHackのさまざまなチームとの連携の強化などが挙げられます。私たちは、電力センサーの1つからのデータを監視システムに取り込み、デバイスが故障しているのか、単に電力が供給されていないのかを簡単に確認できるようにする概念実証を作成することに成功しました。また、イベントの店舗で使用されているPOSシステムとの統合にも取り組んでいます。アイスクリームの売上をグラフ化したいと思いませんか?
最後に、チームが運用するすべてのサービスがオンサイトにあるわけではなく、イベント後も24時間年中無休で稼働するものもあります。これらのサービスもPrometheusで監視したいと考えており、長期的にはPrometheusがフェデレーションをサポートするようになれば、オフサイトのPrometheusを使用してイベントのPrometheusからメトリクスを複製することを計画しています。
締めの言葉
Prometheusの使いやすさと、スケーラブルな監視とアラートをゼロから簡単にセットアップできることに、私たちは非常に興奮しています。
イベント中にFreeNodeの#prometheusチャンネルで私たちを助けてくれたすべての人に、心から感謝します。特にBrian Brazil、Fabian Reinartz、Julius Volzに感謝します。ドキュメントを十分に読んでいなかったことが明らかだった場合でも、助けてくれてありがとうございました。
最後に、dhmonはすべてオープンソースですので、興味のある方はhttps://github.com/dhtech/にアクセスして確認してください。もしこの活動に参加したいと感じたら、QuakeNetの#dreamhackにアクセスして私たちとチャットしてください。もしかしたら、次のDreamHackの構築を手伝ってくれるかもしれませんよ?