ShowMax インタビュー
2016年5月1日筆者: Brian Brazil
Prometheus ユーザーへのインタビューシリーズの第2弾です。ここでは、Prometheus の評価と使用経験について共有していただきます。
ご自身と ShowMax について教えていただけますか?
私は Antonin Kral と申します。ShowMax のリサーチとアーキテクチャを率いています。それ以前は、過去12年間、アーキテクチャと CTO の役割を担ってきました。
ShowMax は、2015年に南アフリカでローンチされたサブスクリプションビデオオンデマンドサービスです。20,000エピソード以上のテレビ番組や映画という豊富なコンテンツカタログを持っています。現在、当社のサービスは世界65カ国で利用可能です。アメリカやヨーロッパでよりよく知られた競合他社がしのぎを削る中、ShowMax はより困難な問題と戦っています。それは、インターネット接続がほとんどないサハラ以南アフリカの村で、どうすれば binge-watch(連続視聴)できるのかということです。すでに世界のビデオストリーミングの35%はストリーミングされていますが、この革命から取り残された場所はまだたくさんあります。
![]()
CoreOS を中心に構築されたプライベートクラスターで主に動作している約50のサービスを管理しています。これらは主に、クライアント(Android、iOS、AppleTV、JavaScript、Samsung TV、LG TV など)からのAPIリクエストを処理しており、一部は内部でも使用されています。最大の内部パイプラインの1つはビデオエンコーディングで、大規模な取り込みバッチを処理する際には400台以上の物理サーバーを占有することがあります。
バックエンドサービスの大部分は Ruby、Go、または Python で書かれています。Ruby でアプリを書く際には EventMachine(MRI では Goliath、JRuby では Puma)を使用しています。Go は通常、大量のスループットを必要とし、あまり多くのビジネスロジックを持たないアプリに使用されます。Python で書かれたサービスには Falcon を使用しており、非常に満足しています。データは PostgreSQL と ElasticSearch クラスターに保存されています。etcd とカスタムツールを使用して、Varnish を設定し、リクエストをルーティングしています。
Prometheus導入前のモニタリング経験について教えてください。
監視システムの主なユースケースは以下の通りです。
- アクティブ監視とプロービング(Icinga 経由)
- メトリクスの取得と、それらのメトリクスに基づいたアラートの作成(現在は Prometheus)
- バックエンドサービスからのログ取得
- アプリケーションからのイベントおよびログ取得
最後の2つのユースケースは、当社のロギングインフラストラクチャ経由で処理されます。これには、サービスコンテナ内で実行されるコレクタが含まれており、ローカルの Unix ソケットでリッスンしています。このソケットは、アプリが外部にメッセージを送信するために使用されます。メッセージは RabbitMQ サーバーを経由してコンシューマーに転送されます。コンシューマーはカスタムで記述されているか、hekad ベースです。主なメッセージフローの1つは、サービス ElasticSearch クラスターに向かっており、これにより Kibana やアドホック検索でログにアクセスできます。また、すべての処理済みイベントは、アーカイブ目的またはさらなる処理のために GlusterFS に保存しています。
以前は、2つのメトリクス取得パイプラインを並行して実行していました。1つ目は Collectd + StatsD + Graphite + Grafana に基づき、もう1つは Collectd + OpenTSDB を使用していました。どちらのパイプラインも、かなりの苦労を伴いました。Graphite の I/O への過剰な負荷、あるいは OpenTSDB の複雑さと不十分なツールに対処しなければなりませんでした。
Prometheusを検討することにした理由は何ですか?
以前の監視システムでの問題から学び、代替品を探しました。候補に残ったのは数件のみでした。Prometheus はそのうちの1つでした。当時、当社のオペレーション責任者であった Jiri Brunclik が、Google の元同僚からこのシステムについて個人的な推薦を受けていたからです。
概念実証はうまくいきました。すぐに動作するシステムを構築できました。また、InfluxDB をメインシステムとして、また Prometheus の長期ストレージとしても評価しました。しかし、最近の動向により、これはもはや当社にとって実現可能な選択肢ではないかもしれません。
どのように移行しましたか?
当初はサービスサーバーの1つで LXC コンテナを実行していましたが、すぐに Hetzner の専用サーバーに移行し、そこでほとんどのサービスをホストしています。PX70-SSD を使用しており、これは Intel® Xeon® E3-1270 v3 Quad-Core Haswell で 32GB RAM を搭載しているため、Prometheus を実行するには十分なパワーがあります。SSD により、保持期間を120日に設定できます。当社のロギングインフラストラクチャは、ローカルでログを取得し(Unix ソケットで受信)、その後、さまざまなワーカーにプッシュするように構築されています。
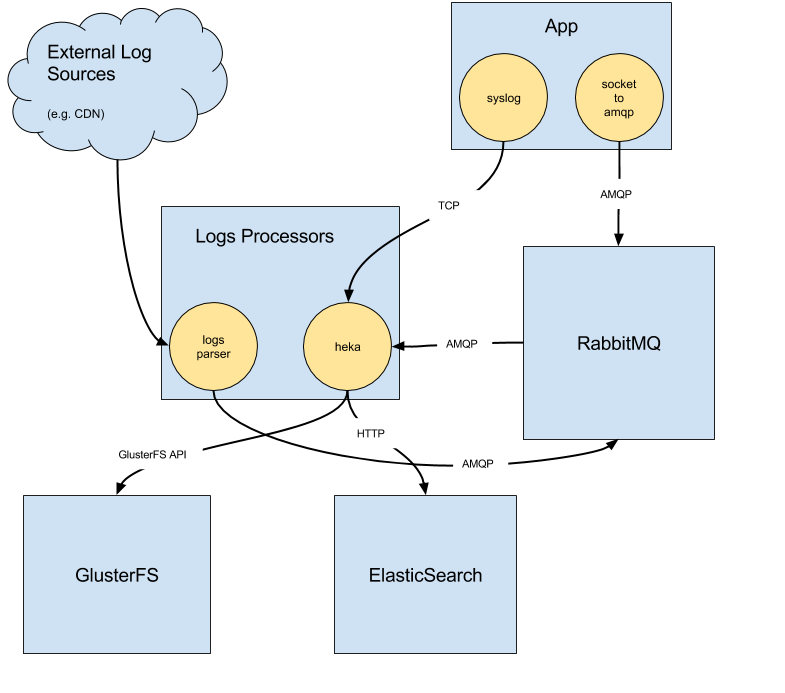
このインフラストラクチャが利用可能になったことで、メトリクスをプッシュすることは論理的な選択肢となりました(特に Prometheus 登場以前)。一方で、Prometheus は主にメトリクスをスクレイピングするパラダイムを中心に設計されています。当社は一貫性を保ち、当初はすべてのメトリクスを Prometheus にプッシュすることを選択しました。prometheus-pusher と呼ばれる Go デーモンを作成しました。これは、ローカルエクスポーターからメトリクスをスクレイピングし、Pushgateway にプッシュする責任を負います。メトリクスをプッシュすることには、いくつかの肯定的な側面(例:サービスディスカバリの簡素化)がありますが、かなりの欠点もあります(例:ネットワークパーティションとクラッシュしたサービスを区別するのが難しくなる)。prometheus-pusher は GitHub で利用可能にしましたので、ご自身で試すことができます。
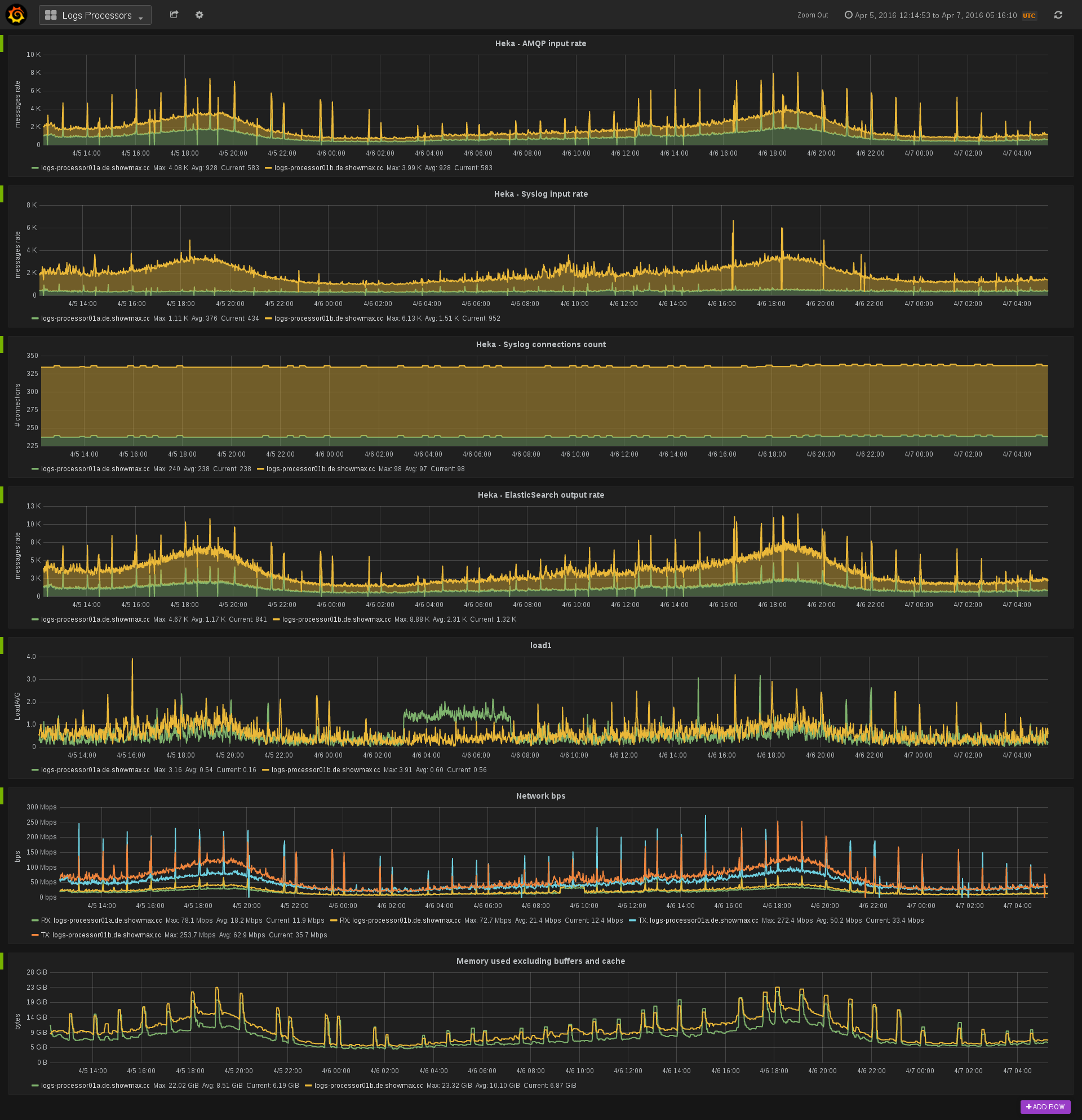
次のステップは、ダッシュボードとグラフの管理に何を使用するかを決定することでした。Grafana との統合は気に入っていましたが、Grafana がダッシュボード構成をどのように管理するかはあまり好きではありませんでした。Grafana は Docker コンテナで実行しており、変更はコンテナの外に保持する必要があります。もう1つの問題は、Grafana における変更追跡の欠如でした。
そのため、git 内で管理されている YAML を受け取り、Grafana ダッシュボード用の JSON 設定を生成するジェネレーターを作成することにしました。さらに、コンテナ内で行われた変更を永続化することなく、新しいコンテナで起動された Grafana にダッシュボードをデプロイすることも可能です。これにより、自動化、再現性、および監査が可能になります。
このツールも Apache 2.0 ライセンスの下、GitHub で利用可能になったことをお知らせできることを嬉しく思います。
切り替え以降、どのような改善が見られましたか?
すぐに実感できた改善点は、Prometheus の安定性でした。それ以前は Graphite の安定性とスケーラビリティに苦労していたため、それが解決されたことは私たちにとって大きな勝利でした。さらに、Prometheus の速度と安定性により、開発者はメトリクスに非常に簡単にアクセスできるようになりました。Prometheus は、DevOps カルチャーを受け入れる上で本当に役立っています。
当社のバックエンド開発者の一人である Tomas Cerevka が、JRuby を使用したサービスの新バージョンをテストしていました。彼はその特定のサービスのヒープ消費量を素早く確認する必要がありました。彼は瞬時にその情報を入手することができました。私たちにとって、このスピードは不可欠です。
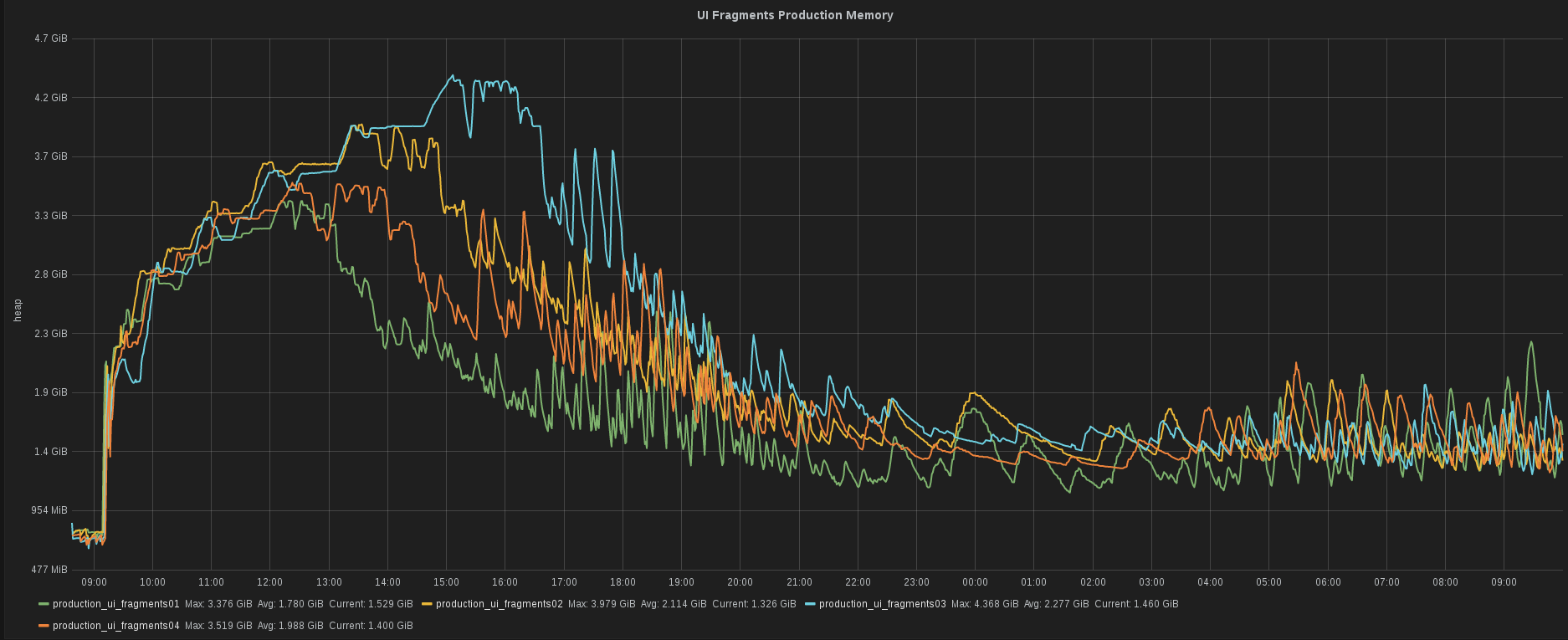
ShowMax と Prometheus の将来について、どのようにお考えですか?
Prometheus は ShowMax の監視において不可欠な部分となり、今後も私たちと共に歩んでいくでしょう。メトリクスストレージ全体を Prometheus に置き換えましたが、取り込みチェーンはプッシュベースのままです。そのため、Prometheus のベストプラクティスに従い、プルモデルに切り替えることを検討しています。
アラートについてもすでに試しています。このトピックにもっと時間を費やし、ますます洗練されたアラートルールを作成したいと考えています。