メトリックタイプの理解
Prometheus は4種類のメトリックをサポートしています
- カウンター
- ゲージ
- ヒストグラム
- サマリー
Counter
カウンターは、増加またはリセットのみ可能なメトリック値です。つまり、前の値より値が減少することはありません。リクエスト数、エラー数などに使用できます。
クエリバーに以下のクエリを入力し、実行をクリックします。
go_gc_duration_seconds_count
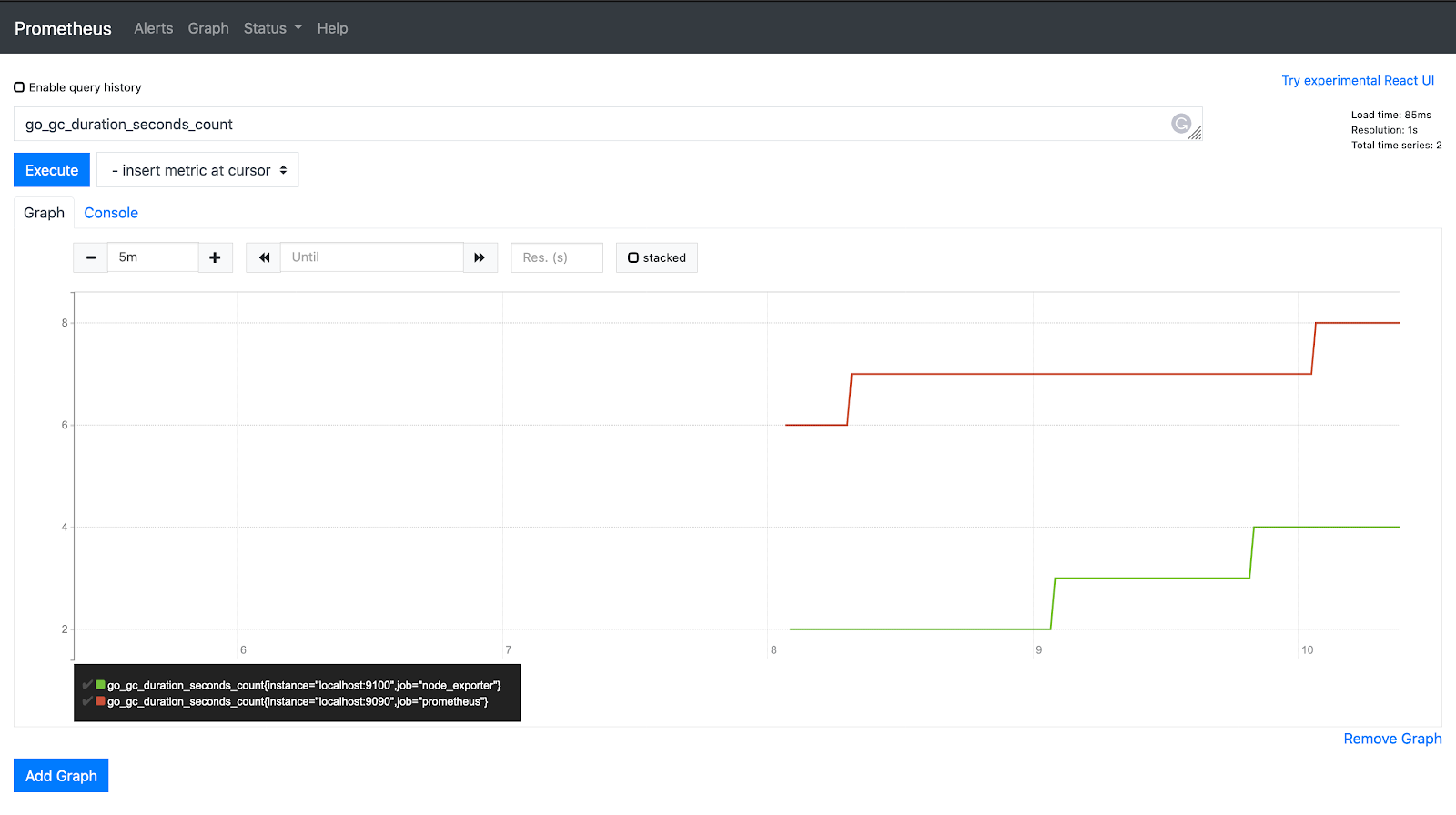
PromQL の `rate()` 関数は、一定期間のメトリック履歴を取得し、1秒あたりの増加速度を計算します。Rate はカウンター値にのみ適用可能です。
rate(go_gc_duration_seconds_count[5m]) 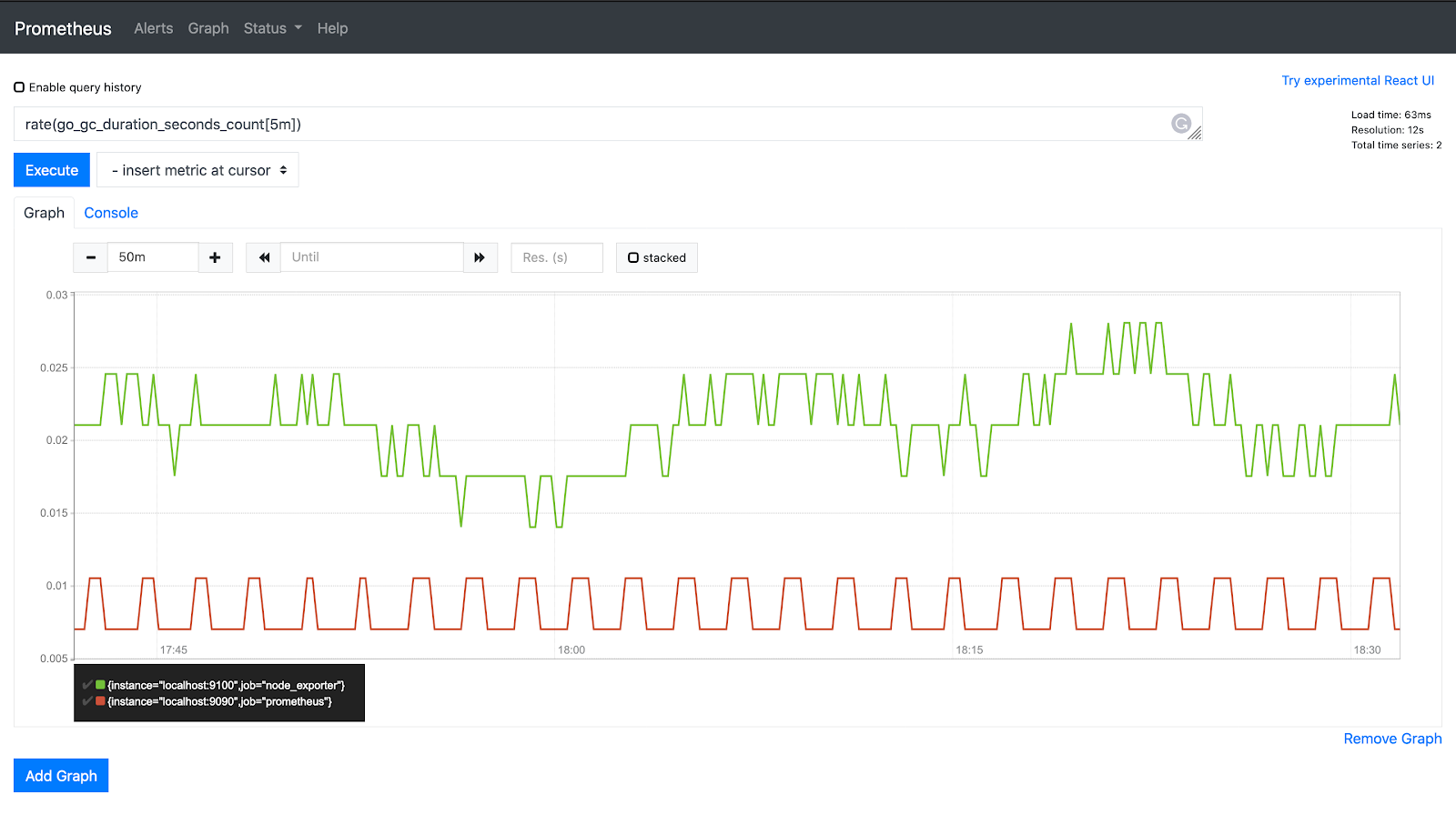
Gauge
ゲージは、増減する可能性のある数値です。クラスター内のポッド数、キュー内のイベント数などに使用できます。
go_memstats_heap_alloc_bytes 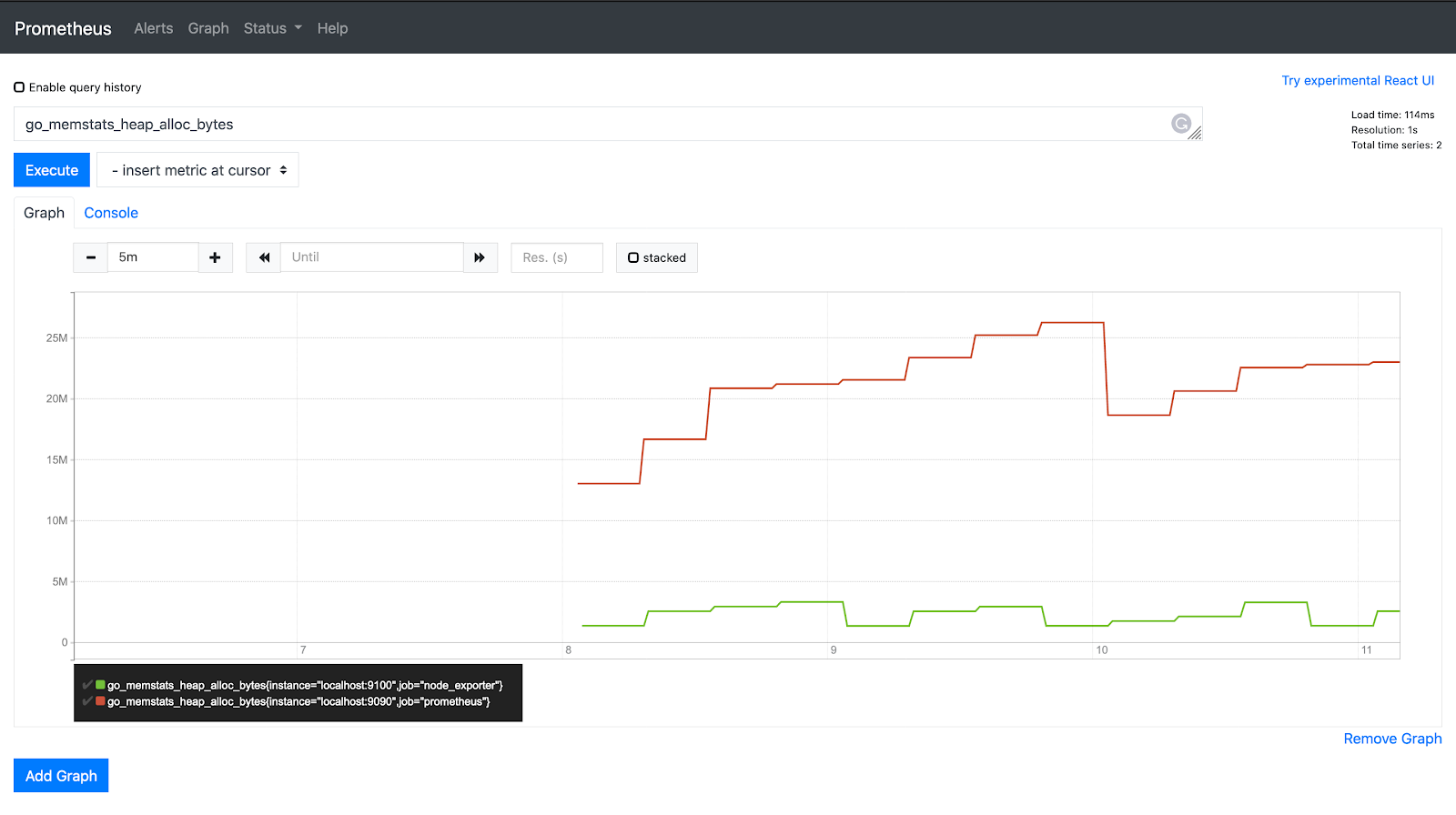
ゲージメトリックには、`max_over_time`、`min_over_time`、`avg_over_time` などの PromQL 関数を使用できます。
Histogram
ヒストグラムは、前の2つと比較してより複雑なメトリックタイプです。ヒストグラムは、バケット値に基づいてカウントされる、あらゆる計算値に使用できます。バケットの境界は開発者が設定できます。一般的な例としては、リクエストへの応答にかかる時間、いわゆるレイテンシが挙げられます。
例: API リクエストの処理にかかる時間を観察したいとします。各リクエストの応答時間を保存する代わりに、ヒストグラムはバケットに保存することを可能にします。時間のバケットを定義します。例えば、0.3 以下、0.5 以下、0.7 以下、1 以下、1.2 以下。これらがバケットとなり、リクエストにかかった時間が計算されると、測定値より大きいバケット境界を持つすべてのバケットのカウントに追加されます。
エンドポイント “/ping” のリクエスト 1 は 0.25 秒かかったとします。バケットのカウント値は次のようになります。
/ping
| バケット | カウント |
|---|---|
| 0 - 0.3 | 1 |
| 0 - 0.5 | 1 |
| 0 - 0.7 | 1 |
| 0 - 1 | 1 |
| 0 - 1.2 | 1 |
| 0 - +Inf | 1 |
注意: +Inf バケットはデフォルトで追加されます。
(ヒストグラムは累積度数であるため、値より大きいすべてのバケットに 1 が追加されます)
エンドポイント “/ping” のリクエスト 2 は 0.4 秒かかりました。バケットのカウント値は次のようになります。
/ping
| バケット | カウント |
|---|---|
| 0 - 0.3 | 1 |
| 0 - 0.5 | 2 |
| 0 - 0.7 | 2 |
| 0 - 1 | 2 |
| 0 - 1.2 | 2 |
| 0 - +Inf | 2 |
0.4 は 0.5 より小さいため、その境界までのすべてのバケットがカウントを増やします。
Prometheus UI でヒストグラムメトリックを探索し、いくつかの関数を適用してみましょう。
prometheus_http_request_duration_seconds_bucket{handler="/graph"}
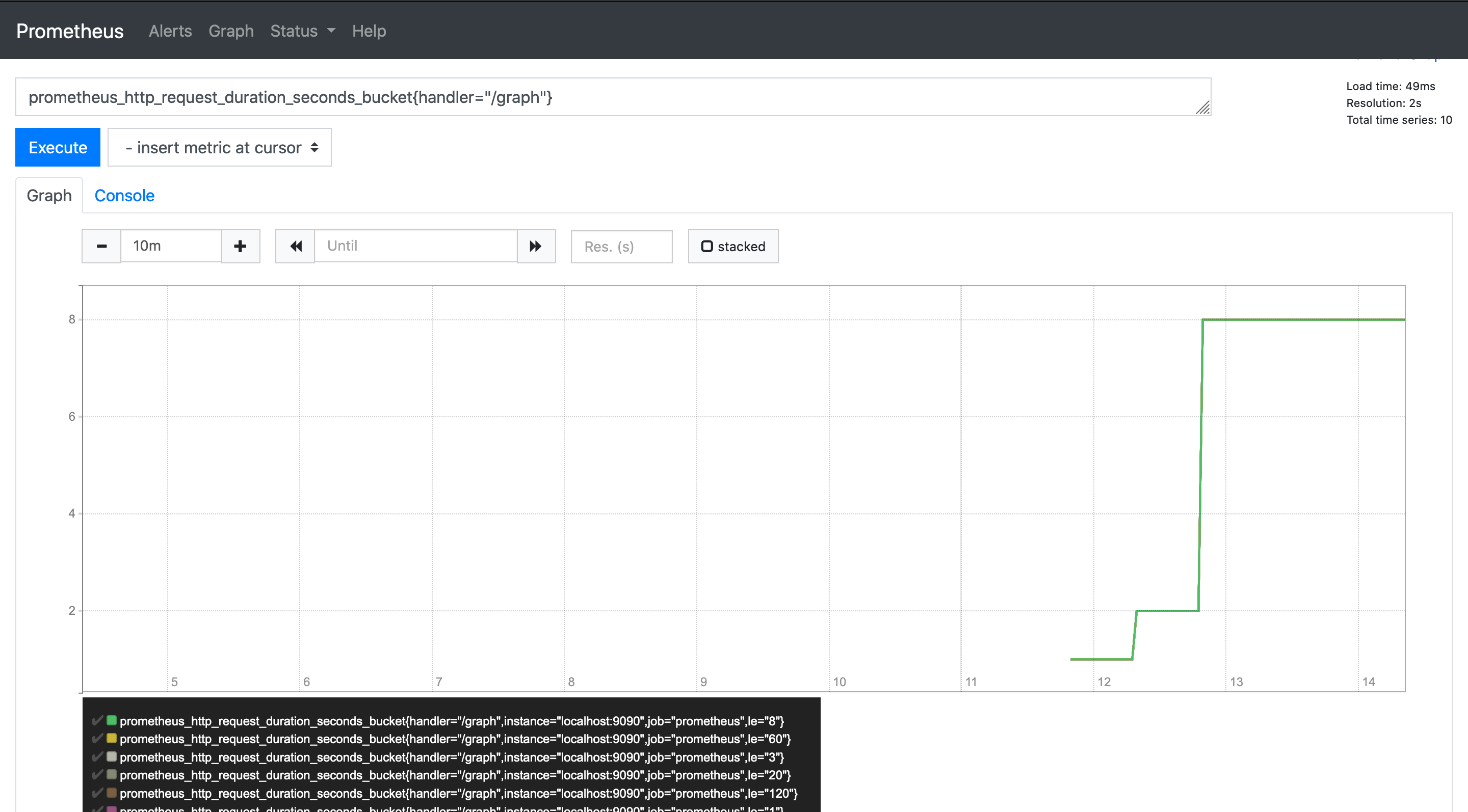
histogram_quantile() 関数を使用して、ヒストグラムからパーセンタイルを計算できます。
histogram_quantile(0.9,prometheus_http_request_duration_seconds_bucket{handler="/graph"})
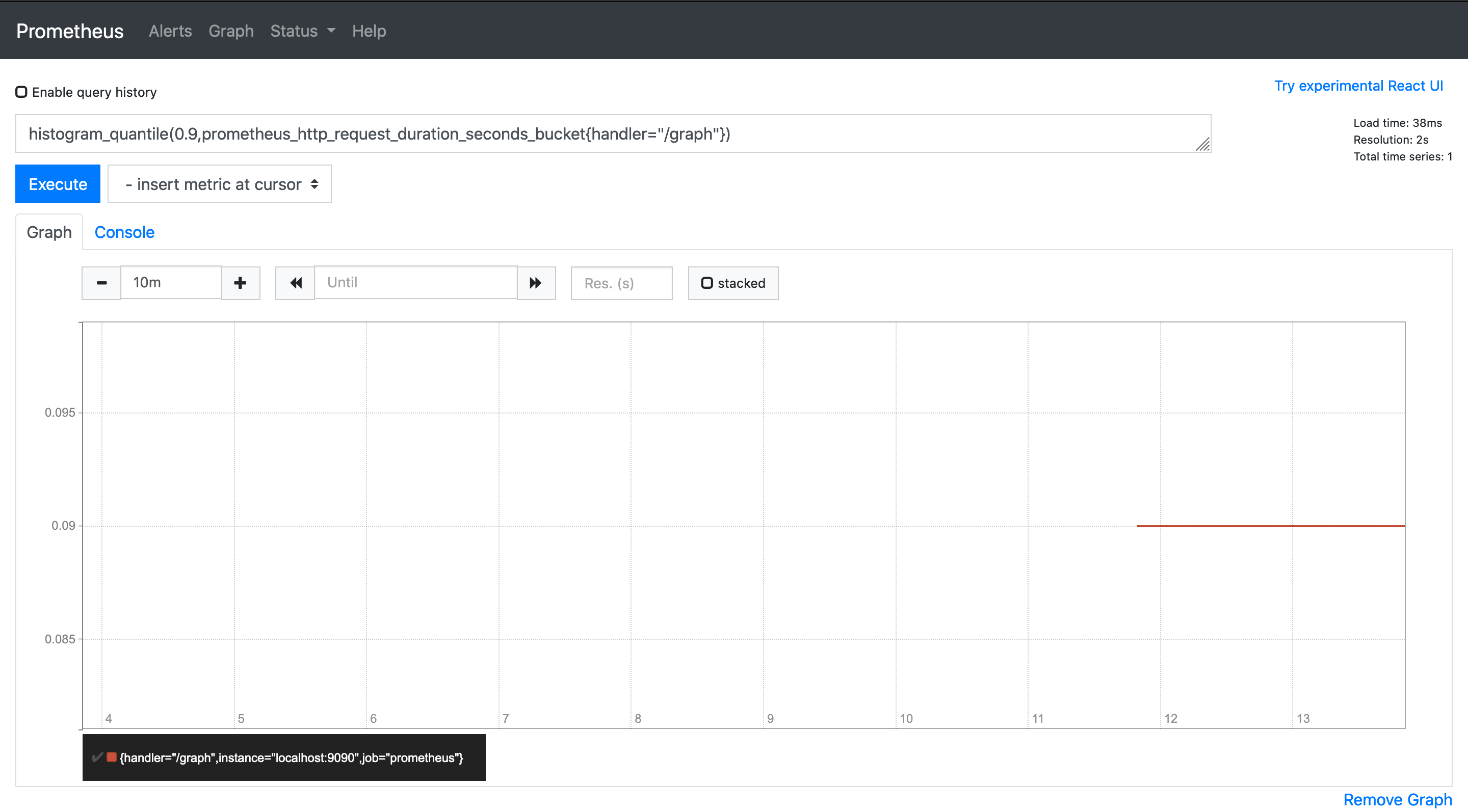
グラフは 90 パーセンタイルが 0.09 であることを示しています。過去 5 分間の histogram_quantile を見つけるには、rate() と時間枠を使用できます。
histogram_quantile(0.9, rate(prometheus_http_request_duration_seconds_bucket{handler="/graph"}[5m]))
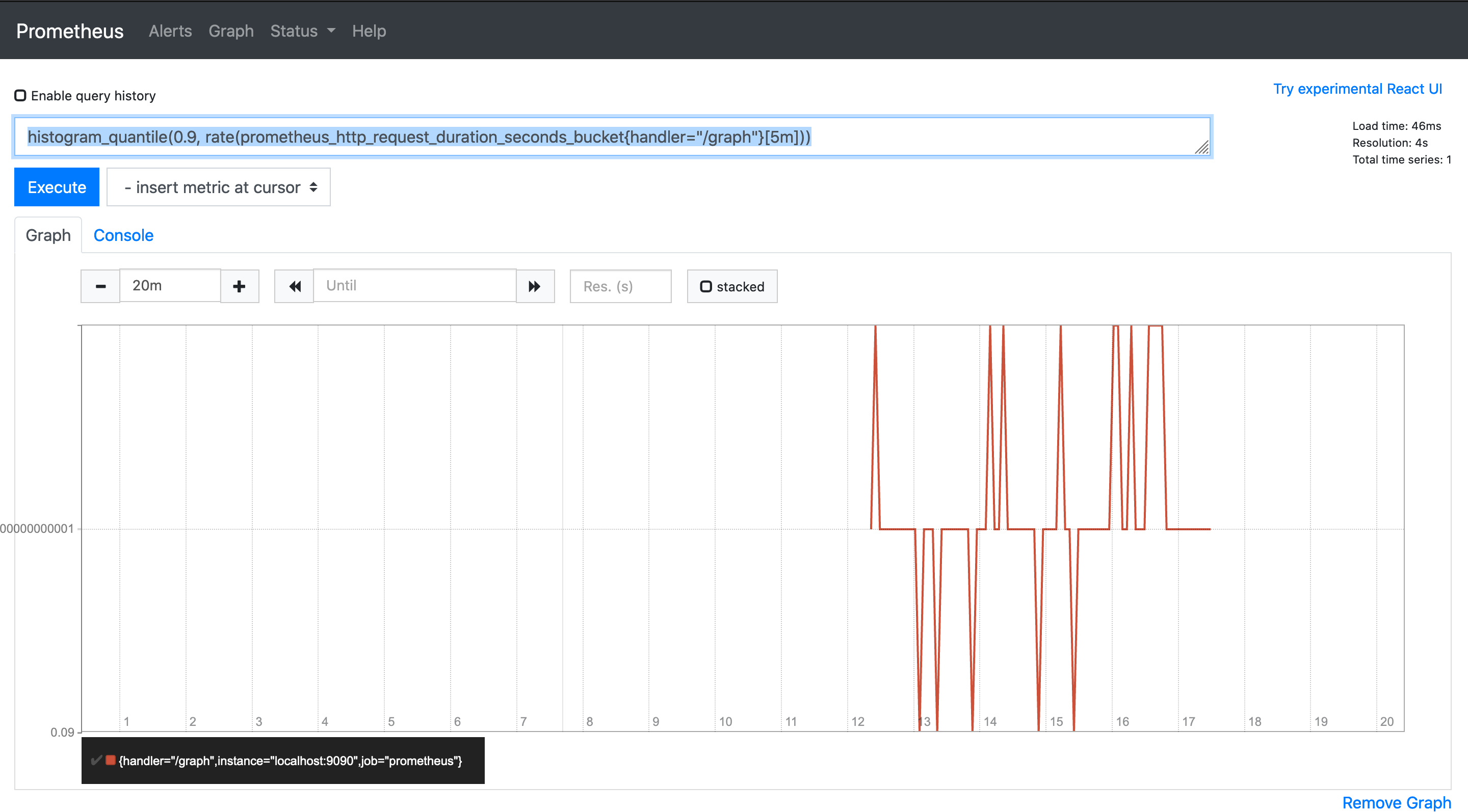
概要
サマリーもイベントを測定し、ヒストグラムの代替手段です。これらはより安価ですが、より多くのデータを失います。これらはアプリケーションレベルで計算されるため、同じプロセスの複数のインスタンスからのメトリックの集約は不可能です。メトリックのバケットが事前にわからない場合に使用されますが、可能な限りヒストグラムをサマリーよりも使用することが強く推奨されます。
このチュートリアルでは、メトリックのタイプと、rate、histogram_quantile などのいくつかの PromQL 操作について詳しく説明しました。